
PostgreSQL Dead Tuples: MVCC, Autovacuum, and Database Bloat

When you think about database performance, you probably focus on query tuning, proper indexing, and caching layers. Yet for many high-churn SaaS applications—chat systems, order pipelines, session stores—the real culprit behind creeping latency and skyrocketing storage isn’t missing indexes or bad queries, but something far more subtle: dead tuples.
In this deep dive, we’ll explore:
What dead tuples are and why they exist
The tuple lifecycle under PostgreSQL’s MVVC engine
Autovacuum, visibility maps, and the mechanics of tuple cleanup
How dead tuples lead to index bloat and disk-space waste
Hands-on strategies to monitor, tune, and reclaim space
By the end, you’ll understand how row-versioning works under the hood—and how to keep your SaaS backend lean, predictable, and lightning-fast.
What are Dead Tuples
In PostgreSQL’s MVCC (Multi-Version Concurrency Control) engine, dead tuples are simply old row versions that linger after updates or deletes. They exist by design: when you UPDATE or DELETE a row, PostgreSQL does not overwrite or immediately remove the old record.
Instead it creates a new tuple with the updated data and marks the old tuple as dead (obsolete). In other words, each tuple carries system columns xmin (insertion transaction ID) and xmax (deletion/update transaction ID), so an updated row spawns a new tuple (new xmin) while its old copy gets an xmax and becomes invisible to future transactions.
Even failed transactions leave dead tuples behind: if a transaction is rolled back after inserting or modifying rows, those tuples are simply marked dead and later cleaned up by vacuum.
In short, dead tuples are obsolete row versions that “still occupy space” until removed. They’re a natural by-product of MVCC, essential for concurrency, but left unchecked they waste space and can slow down queries (by forcing the database to skip over dead entries).
Tuple Lifecycle under MVCC
Each tuple in a PostgreSQL table carries metadata about transactions. The header fields xmin and xmax record which transaction created and which deleted (or updated) the tuple. For example, after an INSERT, the new tuple has xmin=<that transaction> and xmax=0.
On UPDATE, PostgreSQL writes a new tuple with the new values (and a fresh xmin), and sets the old tuple’s xmax to the updating transaction ID. Similarly, on DELETE the existing tuple’s xmax is set and no new tuple is created.
From the viewpoint of a given transaction’s snapshot, a tuple is visible only if its xmin transaction has committed and its xmax transaction has not (or is in the future). For example, if transaction 2 committed before our snapshot, its changes (including creating a new tuple) will be seen; but transaction 1 (still active at snapshot time) and transaction 3 (starting after) will not be seen.
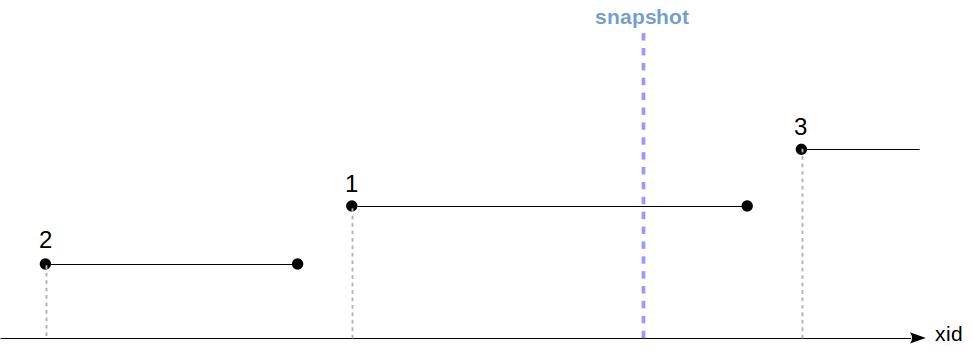
In practice, this means old versions of rows can stick around as “dead tuples.”
For instance, consider a table users(id,name). If we
UPDATE users SET name='Bob' WHERE id=5;,PostgreSQL actually inserts a new row id=5,name='Bob' under the hood, and marks the old id=5,name='Alice' row as dead.
The dead row remains on disk (increasing n_dead_tup statistics) until a cleanup process removes it. Likewise, aborted transactions leave dead row versions behind.
An hands-on example showed deleting 1,000,000 rows from a 10M-row table resulted in n_dead_tup = 1000000. In MVCC, every UPDATE or DELETE grows the table with a new row and a dead row. This avoids write-locking readers, but requires later cleanup.
Autovacuum and Visibility Maps
PostgreSQL relies on VACUUM to remove dead tuples and reclaim space. By default, VACUUM runs automatically in the background (the autovacuum daemon) to prevent bloat. A plain VACUUM pass scans each table, deletes dead tuple pointers, and marks their space free within the table; it does not immediately return space to the OS (that requires VACUUM FULL or CLUSTER).
Under the hood, VACUUM checks each tuple’s header to see if it is now past all transaction snapshots; if so, it can be removed. A key optimization is the visibility map: a bitmap per table page that tracks whether all tuples on a page are already known visible (or frozen) to all transactions.
When a page has no more dead or unfrozen tuples, its visibility map bit is set. On the next vacuum, pages marked “all-visible” can be skipped entirely (since no cleanup is needed). This greatly speeds up vacuum on large tables.
The visibility map also empowers index-only scans: if the map indicates a page’s tuples are all visible, PostgreSQL can satisfy an index-only scan without touching the heap page.
Autovacuum runs when certain thresholds are reached. The common trigger is a table’s dead tuple count: once the number of dead rows exceeds
autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor * live_row_countVACUUM kicks in. By default this means a table is vacuumed when it has more dead rows than 50 + 20% of its live rows (whichever is larger)pganalyze.com. Autovacuum is also forced by transaction ID age to prevent wraparound: if the oldest unfrozen XID on a table exceeds autovacuum_freeze_max_age (200M by default), vacuum runs to “freeze” those tuplesstormatics.tech. In summary, PostgreSQL automatically vacuums tables both proactively (preventing billions of old XIDs) and reactively (cleaning up excessive dead tuples).
Even with autovacuum, very long-running transactions can delay cleanup. Any active transaction holds a “horizon” that blocks vacuuming tuples that might still be visible to itpostgrespro.com. The diagram below shows how the transaction horizon works: once all transactions older than a point have finished, tuples older than that horizon can be vacuumed.
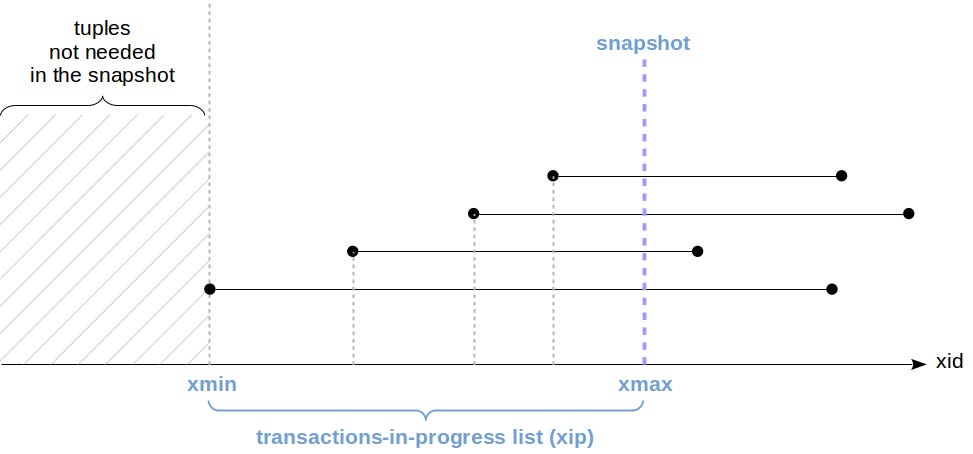
xmin). Only once all prior transactions complete (the horizon moves right) can those dead tuples be safely reclaimed Bloat and Index Infill
When dead tuples accumulate faster than they are removed, tables and indexes bloat. Dead tuples still occupy table pages, so scans read through more pages.
Dead tuples get stored alongside live tuple causing increased I/O and slower queries. Indexes suffer similarly: index entries pointing to deleted rows are not immediately purged. These invalid index entries accumulate, making the index larger and slower.
In other words, “when rows are updated or deleted, the associated indexed values are not immediately purged…over time these ‘dead’ index entries accumulate and contribute to index bloat”.
The performance hit can be stark: in a demo, deleting 10% of a large table (1M rows) doubled a SELECT count(*) time (from ~0.58s to ~1.36s). Bloated tables also mean longer backups and replication lags. In sum, excessive dead tuples waste disk and I/O: scanners must sift through dead rows, and larger indexes mean slower index scans.
Monitoring and Metrics
Good observability is key to catching dead-tuple issues early. PostgreSQL’s statistics collector provides several useful views. For example, pg_stat_user_tables (or pg_stat_all_tables) shows running counts of live and dead tuples per table. A simple query like:
SELECT schemaname, relname, n_live_tup, n_dead_tup
FROM pg_stat_all_tables
WHERE n_dead_tup > 0;will list all tables that currently have dead tuples. This would show n_dead_tup = 1000000 for the bloated table. For deeper analysis, the pgstattuple extension gives exact bloat metrics. After installing it, run:
CREATE EXTENSION IF NOT EXISTS pgstattuple;
SELECT table_len, tuple_count, dead_tuple_count, dead_tuple_len
FROM pgstattuple('schema.your_table');This returns the total table size, number of live vs. dead tuples, and bytes wasted on dead tuples. Seeing a high dead_tuple_count or large dead_tuple_len percentage is a red flag.
You can also inspect the autovacuum log activity. In postgresql.conf, set for example:
log_autovacuum_min_duration = 0 # log all autovacuum runsThen check the logs: each autovacuum report will include how many tuples were removed from each table. Together, these tools let you track which tables are building up dead tuples and whether autovacuum is keeping up.
Autovacuum Tuning
If you identify tables with growing dead-tuple counts, you can tune autovacuum to help. General advice includes lowering the thresholds so vacuum runs more often. For instance, in postgresql.conf or via SQL you might set:
ALTER TABLE schema.your_table
SET (autovacuum_vacuum_threshold = 100, autovacuum_vacuum_scale_factor = 0.05);This makes autovacuum kick in after 100 + 5% dead tuples, instead of the default 50+20%. Globally, you can also adjust autovacuum_max_workers (to allow more concurrent vacuums), autovacuum_cost_limit (to let vacuums work harder), and maintenance_work_mem (to give each vacuum more memory). The goal is to vacuum frequently enough that bloat never gets out of hand.
If autovacuum isn’t enough, manual interventions help: run VACUUM on busy tables during off-hours, and consider VACUUM FULL or CLUSTER on tables with extreme bloat. VACUUM FULL rewrites the table entirely to reclaim space, but it takes an exclusive lock, so use it judiciously. For indexes, periodic rebuilds are advised. For example:
REINDEX INDEX CONCURRENTLY schema.some_index;This rebuilds the index without locking the table, purging dead entry pointers.
Maintenance Checklist
In practice, a healthy Postgres maintenance strategy might include:
Regular monitoring: Query
pg_stat_user_tablesand usepgstattupleto find tables with high dead-tuple percentages.Autovacuum tuning: If a particular table bloat grows, lower its
autovacuum_vacuum_scale_factoror raiseautovacuum_vacuum_thresholdso that it vacuums more aggressively.Vacuum scheduling: Ensure autovacuum is enabled and not disabled on critical tables. If necessary, schedule manual
VACUUM (VERBOSE, ANALYZE)runs during low-traffic windows to force cleanup. Verbose output will report how many dead tuples were removed.Statistics updating: Run
ANALYZE(orVACUUM ANALYZE) regularly so the planner knows current table sizes. This ensures better query plans even as dead tuples come and go.Index care: Rebuild or
REINDEXindexes on heavily updated tables periodically. For very large tables where downtime is a concern, considerpg_repackto rebuild tables/indexes online.Alerting: Set up alerts (for example via PG monitoring tools) on metrics like high
n_dead_tup, rapidly growing table sizes, or long-running transactions (which can prevent vacuums). Early warning lets you intervene before queries slow dramatically.
Example psql output might look like this:
postgres=# SELECT relname, n_live_tup, n_dead_tup, last_autovacuum
FROM pg_stat_user_tables
WHERE n_dead_tup > 0;
relname | n_live_tup | n_dead_tup | last_autovacuum
----------+------------+------------+------------------
orders | 100000 | 2500 | 2025-05-03 01:15
events | 50000 | 12500 | 2025-05-02 23:47
(2 rows)And running VACUUM VERBOSE events; (after adjusting thresholds) might show output like:
VACUUM VERBOSE events;
INFO: vacuuming "public.events"
INFO: "events": removed 12500 dead row versions, 0 pages recycled, 0 index pages recycled
VACUUMConclusion
Dead tuples are normal under PostgreSQL’s MVCC design, but they must be managed. Left unchecked, they lead to table/index bloat and wasted I/O. By understanding how PostgreSQL versions rows, uses autovacuum and visibility maps to clean up, and by monitoring key statistics, engineers can keep their databases lean and performant.
In other words, mastery of row-version management is essential for any team building a high-performance SaaS backend: keeping the database tidy of dead tuples helps ensure predictable query latency, efficient use of disk, and scalable throughput.
References
Improving PostgreSQL efficiency by handling dead tuples
Scenarios That Trigger Autovacuum in PostgreSQL
MVCC in PostgreSQL — 4. Snapshots
Dead Tuples In Focus — Vol I: Enhancing PostgreSQL Performance 🚀
https://www.postgresql.org/docs/current/sql-vacuum.html#:~:text=,updated%20tables