
Hotel Reservation System: Distributed Transactions, Idempotency, Concurrency.


In the past, we have talked about the concept of distributed transactions and different approaches to implementing it in a distributed system. If you missed out on that issue, you can read it here.
We will be taking a deeper look at designing an hotel reservation system design. We will integrate the concept of distributed transactions in a more practical way by designing an hotel reservation system. We will also explain different approaches to each concept and the best possible scenarios to implement them while designing an application.
In this issue, we will discuss the following:
High level architecture of an hotel reservation system
APIs and capacity estimations
How do we ensure atomic transactions in a microservice architecture
How to avoid double booking by the same user.
Let’s go…
Functional Requirements
Search for room types
Reserve a room type
Handle payments through third parties
Optional Scope
Notification system
Analytics system
Non-functional Requirements
Customers from all around the world can book a room type
Highly available search service
Highly consistent booking service
Booking should be able to handle concurrent booking request
Latency should be as low as possible
Scale:
Daily active searches: 70K
Daily bookings: 7k
Daily Room listings: 70
APIs & Capacity Estimations
APIs
Search endpoint:
Payload: location, check-in and check-out date, number of people
Book reservation endpoint:
Payload: room_type, customer_id, guest_size, no_of_rooms
Get single reservation endpoint
Parameter: reservation_id
Cancel reservation endpoint
Parameter: reservation_id
Capacity Estimates
TPS Estimations
Formula: Number of Transactions/Total Time (in seconds) = TPS
Search:
70k transactions/86400 seconds (a day) = ~0.8 TPS
Reservation:
7k transactions/86400 seconds (a day) = ~0.08 TPS
Storage Estimates
Formula: Room Listings per Day * Size per Listing * Days = Total Data Size
Hotel listing Table
Record size: 1KB
70 room listings per day * 1KB * 365 days = 24.91MB/year
< 1GB storage for 5 years
Reservation Table
record size: 500B
70k daily reservations * 500B * 365 = 11.91GB/year
~ 60 GB storage for 5 years
Base on our capacity estimations, what architecture is best suited?
Our storage estimates are not really compelling enough for a distributed system from scratch, but we are choosing this architecture for a couple of other reasons:
Firstly, preventing our system from having a single point of failure. The tightly integrated nature of a monolith architecture means that if one critical component fails, it can potentially bring down the entire application.
Secondly, we want our system to scale independently. We have a potential to grow exponentially, so our storage may not be too large currently, but if we market our application efficiently and solve our customers’ pain point, we might be blowing up in the nearest future.
Lastly, we could possibly integrate other services in the future like analytics, notification services. We want every possible integrations in the future to be seamless.
High Level Architecture
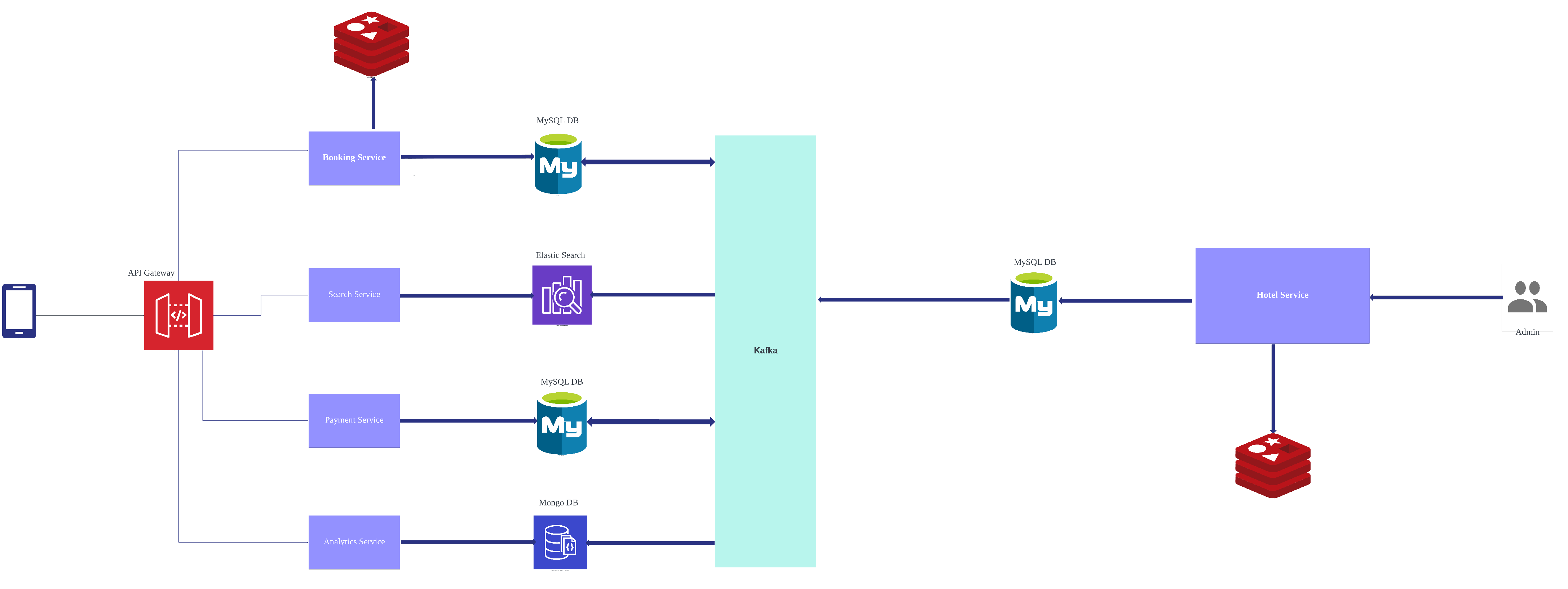
Architectural Pattern
The following are short descriptions of the core services in the design above. What are their purpose, and how do they communicate with other services:
Hotel Service: This service manages hotel listings on the platform and includes detailed information, photos and availability of hotels. The service has its designated database where hotels’ record, properties and current status are kept. Also, to ensure high access speed and efficiency, the data is cached.
Booking Service: This service manages customers’ bookings and maps them to listed available hotels. It has its own database that contains booking details, customers’ booking status and change history. It also communicates with Payment Service and hotel Service through Kafka. For example, when a customer requests to make a reservation, after completing all the necessary steps, it calls payment service and waits for a successful message to complete reservation. If payment is successful, it sends request to hotel service to make necessary updates on hotel status.
Search Service: This service manages customers’ search-related queries for available hotel listings on the platform. It’s handled by Elastic Search considering the ease of performing full-text search and its potential for high scalability with large amount of data.
Payment Service: This service processes payment information, transaction history and billing data, enabling customers to make payments securely.
Analytics Service: This service is not yet fully functional, however, we are currently dumping customers’ search data, booking behaviors into a Mongo DB for future data analytics.
Room Reservation Flow
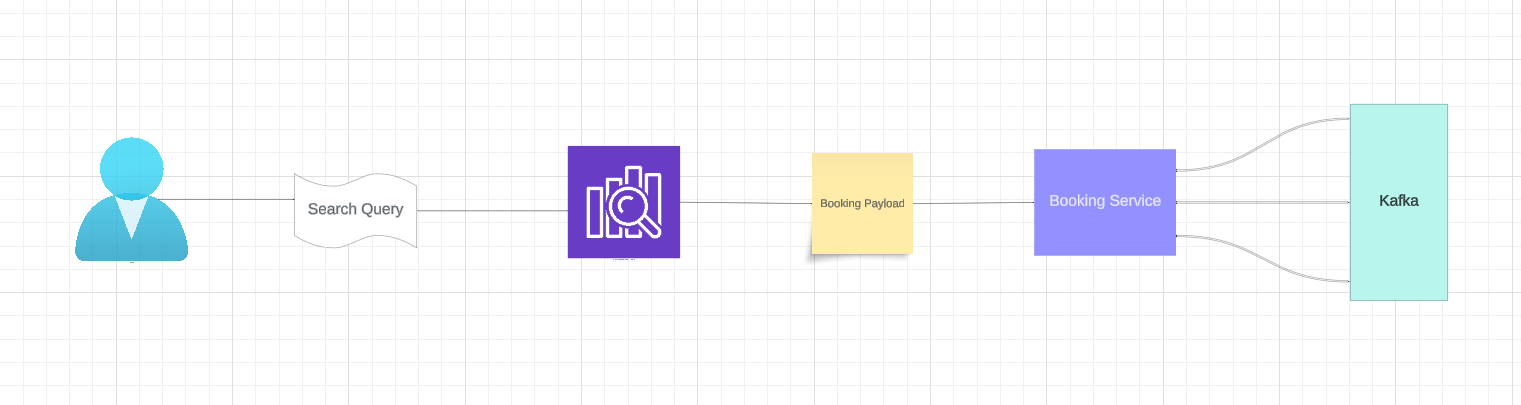
The room reservation flow is the most critical part of our application. So let’s talk about it. There are two possible ways a customer could get to the booking flow: the search service, or the hotel listing recommendation feed determined by an algorithm. We will be focusing on the search service method.
When a user searches for an hotel from our elastic search service, and they get to send the payload to the booking service. The booking service has multiple number of actions to carry out in order to book a room successfully.
The booking service has to check the room type table for availability of the customers’ chosen room type. If the room is not available, it throws an error and aborts the request. If available, the booking service has to update the room type availability table.
Secondly, the booking service will integrate and check for the completion of payment. The Payment service is a third party, so the request has to be handled with caution. If the Payment service returns with a successful response, we proceed to the next stage of the booking process, else we abort the request and returns the error to the customer.
Thirdly, the booking service will have to update the booking information in the customers’ and business booking information table.
Finally, we update the booking information, the selected room type is either marked unavailable or its count incremented so as to prevent other customers from booking.
Optionally, the booking service could also send some payload to the Analytics service for future user behavior analysis.
Critical issues to resolve so far.
The transactions need to be atomic. Atomicity in database transaction means either all of the steps enumerated above succeeds together or those steps
Secondly, how do we avoid multiple customers reserving the same room. How do we effectively monitor the status of a room type such that when it is fully booked, we prevent subsequent requests from having access to it.
Lastly, how do we avoid double booking by the same customer. Should the customer decide to click the “Book” button twice in very quick successions. How do we avoid booking twice?
How do ensure atomic transactions in a microservice architecture?
Maintaining and performing multiple actions in a monolith system is fairly straightforward without much complexities. However, in our system, we have decided to build in microservice architectural pattern, it means transactions is happening across multiple services simultaneously. The challenge of maintaining atomicity across multiple microservices is called distributed transactions.
The challenge is that you want to make sure that for any given business logic, any changes you make to the state of service A's database table also affect service B's database table.
It means we have to execute these four steps mentioned above with distributed transactions.
There are three main approaches to solve this challenge. Two-Phase Commit (2PC), the Saga Pattern and Event Sourcing. We will discuss the former two in this issue.
We have discussed in detail the concept of distributed transactions here. We also discussed the Two-Phase Commit and Saga Pattern’s Orchestration and Choreographed approach. Please refer to that issue for deeper grasp of this concept.
Moving on, the Two-phase commit is an algorithm for achieving atomic transaction commit across multiple nodes. An atomic transaction basically means that all of the 2PC participating nodes have to abort together or successfully commit together.
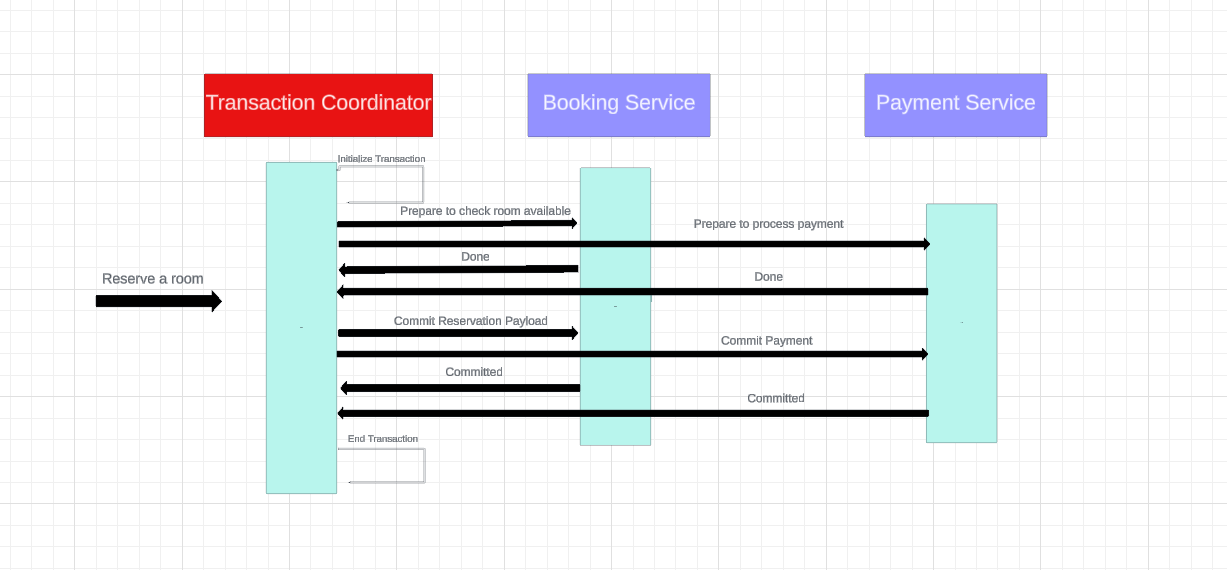
In this protocol, a transaction coordinator is responsible for ensuring that all participants in the transaction agree to commit the transaction.
The coordinator first sends a “prepare to commit” message to all participants: booking service, payment service, booking information service, and if all participants respond positively, it sends a “commit” message to all participants.
If any participant responds negatively, the coordinator sends an “abort” message to all participants, and the transaction is rolled back.
One main drawback to this approach is deadlock where two transactions mutually lock each other. Transaction Deadlocks happen when two or more transactions wait for each other to release locks in a database.
Consider a situation where two customers attempt to book the two of the only available room type in a hotel. Customer A wants room type 1 and 2, Customer B wants room type 1 and 2. Customer A successfully gets a lock on room type 1 and Customer B successfully gets a lock on room type 2.
This is an example of a deadlock transaction. There are some methods to solve this problem, we could implement a TTL on each locks. And with the help of the database, it will automatically release the locks after the stipulated lock period is elapsed.
But the underlying message is, it becomes unsustainable to maintain at a larger scale. Performing this on a massive database table containing potentially billions of entries and with constantly changing rows. The system's latency will rise if many rows are attempted to be locked for numerous transactions at the same time. We call this the long-living transaction. locking a large table for an extended length of time.
This brings us to the second approach: The Saga Pattern.
In this approach, the distributed transaction is fulfilled by asynchronous local transactions on related microservices. The microservices communicate with each other through an event bus (Kafka).
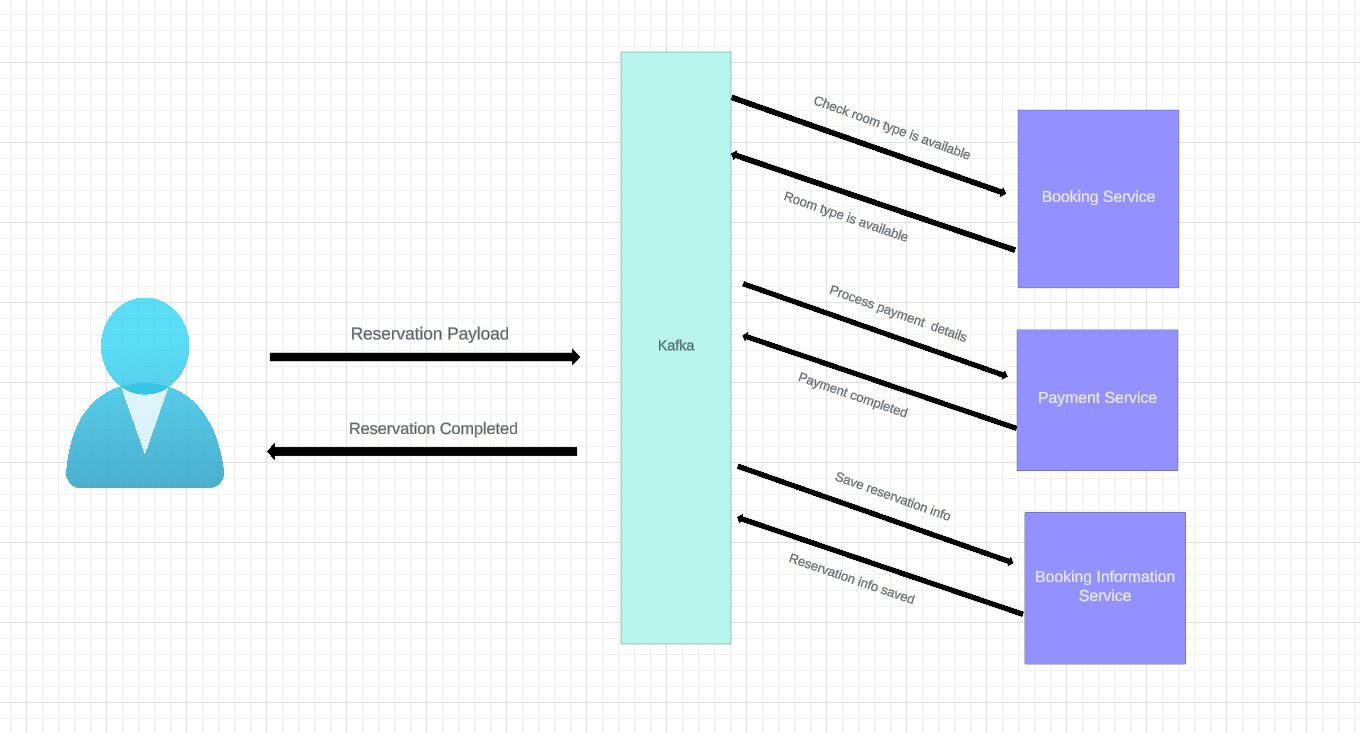
In this case, the customer requests the system to Reserve a Room. The Choreographer emits an event Check Room Type is Available, marking the start of the transaction. The Booking Service listens to this event and checks whether room type is available, if it’s available it emits an Room Type is Available event.
The Payment Service listens to the Room Type is Available event and starts processing the reservation payment details. After it’s completed, the Payment service emits a Payment Completed event.
The Booking Information Service listens to the Payment Completed event and persist the booking information to the database, then emits a Reservation info saved event. The Booking Service listens to this event and finally updates the Booking service status as “booked”. Which in this example means the end of the transaction.
All the event based communication between microservices happen via the Event Bus and is Choreographed by another system to address the complexity issue.
The saga pattern approach to ensuring atomic transactions is more reliable and scalable for the volume of data our system has the potential to reach.
This also helps solve the second critical concern. How to prevent multiple customers from reserving the same room. By using atomic transactions, we can ensure that a series of operations (e.g., checking room availability and making a reservation) either succeed as a whole or fail completely.
This also helps maintain data consistency and avoids scenarios where one user reserves a room while another user is also trying to reserve the same room simultaneously.
How to avoid double booking by the same user?
The second critical scenario we need to consider is what happens when the user clicked “Reserve” twice in very quick succession. How do we avoid booking twice?
There are two ways we can avoid this. Using an idempotent key or using JavaScript client side to disable the buttons. The latter is not so efficient, so we will discuss the former in detail.
How do we implement an idempotent key?
An operation is said to be idempotent if performing it multiple times has the same effect as performing it once.
We can integrate it into our request in four steps:
The client generates and includes a unique idempotent key in the reserve room request. It could anywhere, such as in the headers, request body, or even as a query.
We can implement a middleware on the server side that checks this key to determine whether the request has already been processed.
If the server has already processed a request with the same key, we ignore subsequent requests or respond with the same result without altering the database.
If the server hasn't processed any request with that specific key, it processes the request and associates the key with the operation.
Rounding up…
In conclusion, we have examined how to design a hotel reservation system, its capacity estimation, high level architecture of its different services, communication between the services using Kafka, preventing multiple customers from reserving the same room by ensuring the distributed transactions between microservices are atomic.
We also discussed the possible ways of preventing a customer from clicking the action button twice sending the same request twice using idempotent keys.
Other possible concepts we will discuss in upcoming issues is how to scale our application to handle millions of request without breaking; how the API gateway also acting as a load balancer in ensuring scalability, availability, and efficient distribution of incoming requests across multiple servers or services within our system.
If you enjoyed this issue, be sure to subscribe to our newsletter to never miss our upcoming issues.
See You Soon!