
Distributed Transactions in Microservices


Building a distributed system that handles transactions across the different integrated systems can be very complex and costly because it involves a high level of coordination between multiple services, networks, and databases.
There are a number of significant challenges attached to maintaining consistent and highly efficient distributed transactions in a distributed system. One of the more prominent problems is how we keep the transactions atomic; atomicity means that in a database transaction, either all steps are completed or no steps are completed at all.
In this week’s issue, we will discuss the following:
What is a distributed transaction?
The challenges of implementing distributed transactions in a microservice architecture
The two-phase commit and the saga pattern are some of the industrial standards for implementing distributed transactions in a microservice architecture.
Let’s discuss.
In traditional monolith applications, you would usually have a service having interactions with multiple tables in the database. Performing database operations like updating is fairly straightforward.
An example is updating operations on two tables simultaneously for one business flow. For the most part, it would be sufficient to execute a single transaction that locks both table rows at first, updates the locked rows, and then releases the lock.
It is more difficult to carry out the same task with this same method in a microservice architecture. In this instance, you are attempting to update two separate services, each of which has two separate databases and, most likely, two separate tables that need to be updated.
The challenge is that you want to make sure that for any given business logic, any changes you make to the state of service A's database table also affect service B's database table.
We also want to rollback service A's transaction if the table is updated and the table transaction for service B fails to commit the updated state.
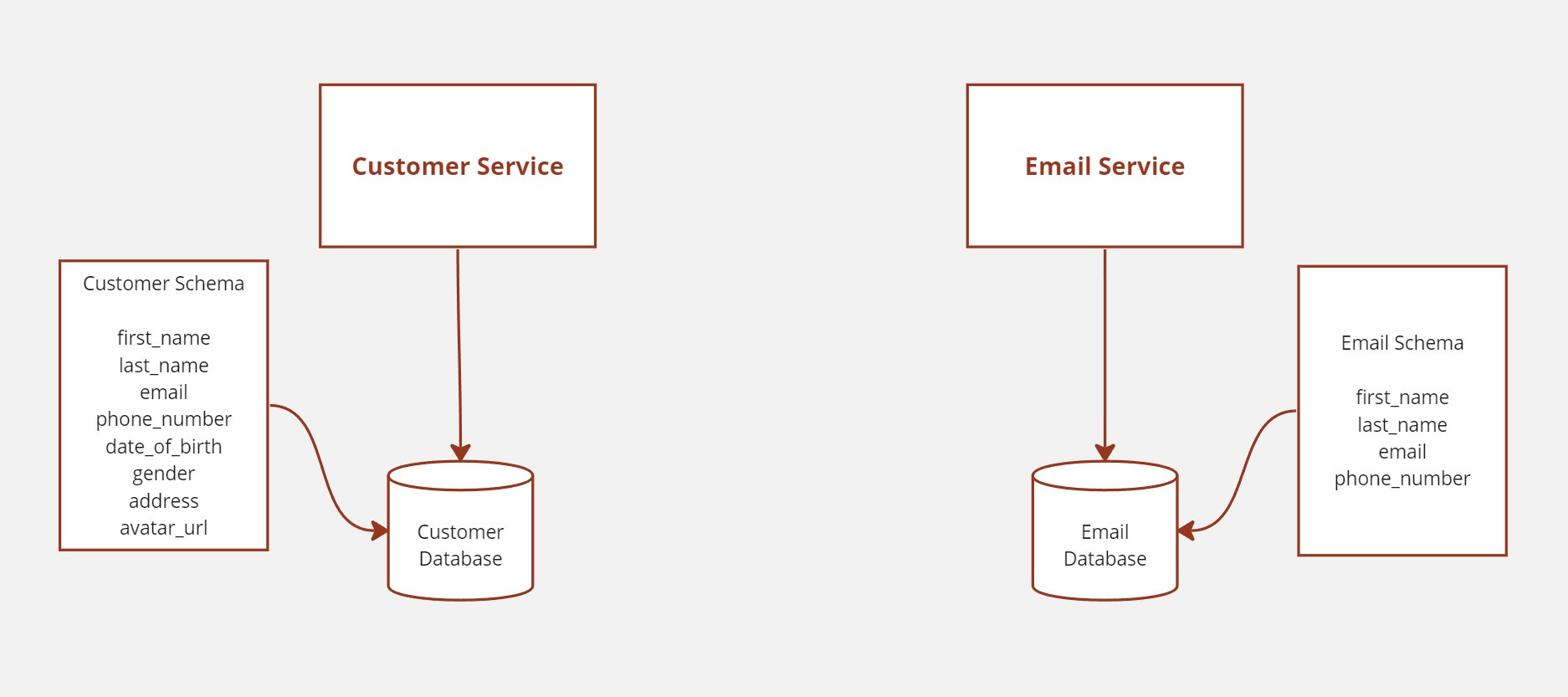
Suppose that email and customer service are the two business apps in our microservice architecture. During onboarding, the application collects user credentials, which it uses to send emails at different times throughout its lifetime.
The application is made in such a way that customer service retains client credentials and sends certain customer credentials to the email service for data redundancy. Essentially, the email service uses a customer table that collects the first name, last name, email, phone number, and any other information needed to send an email to a client on its own without involving customer support.
But what happens when a customer updates their phone number? We have to simultaneously update both the customer and the email service.
This case perfectly illustrates the challenges associated with managing a distributed transaction: how can we make sure that, when the customer table in the customer service is updated, the customer table in the email service is updated in a corresponding way?
There are a number of ways to carry out this kind of transaction in a microservice architecture.
Two-Phase Commit
Two-phase commit (also known as 2PC) is an algorithm for achieving atomic transaction commit across multiple nodes. An atomic transaction basically means that all of the 2PC participating nodes have to abort together or successfully commit together.
It's a popular approach for handling problems with distributed transactions. How do we incorporate the aforementioned issue into a two-phase pledge?
Each service would have a worker assigned to it, and after that, we would develop a new entity called the Transaction Coordinator. The transaction coordinator's role is to mediate disputes between the two services.
The two-phase commit is implemented in four cycles:
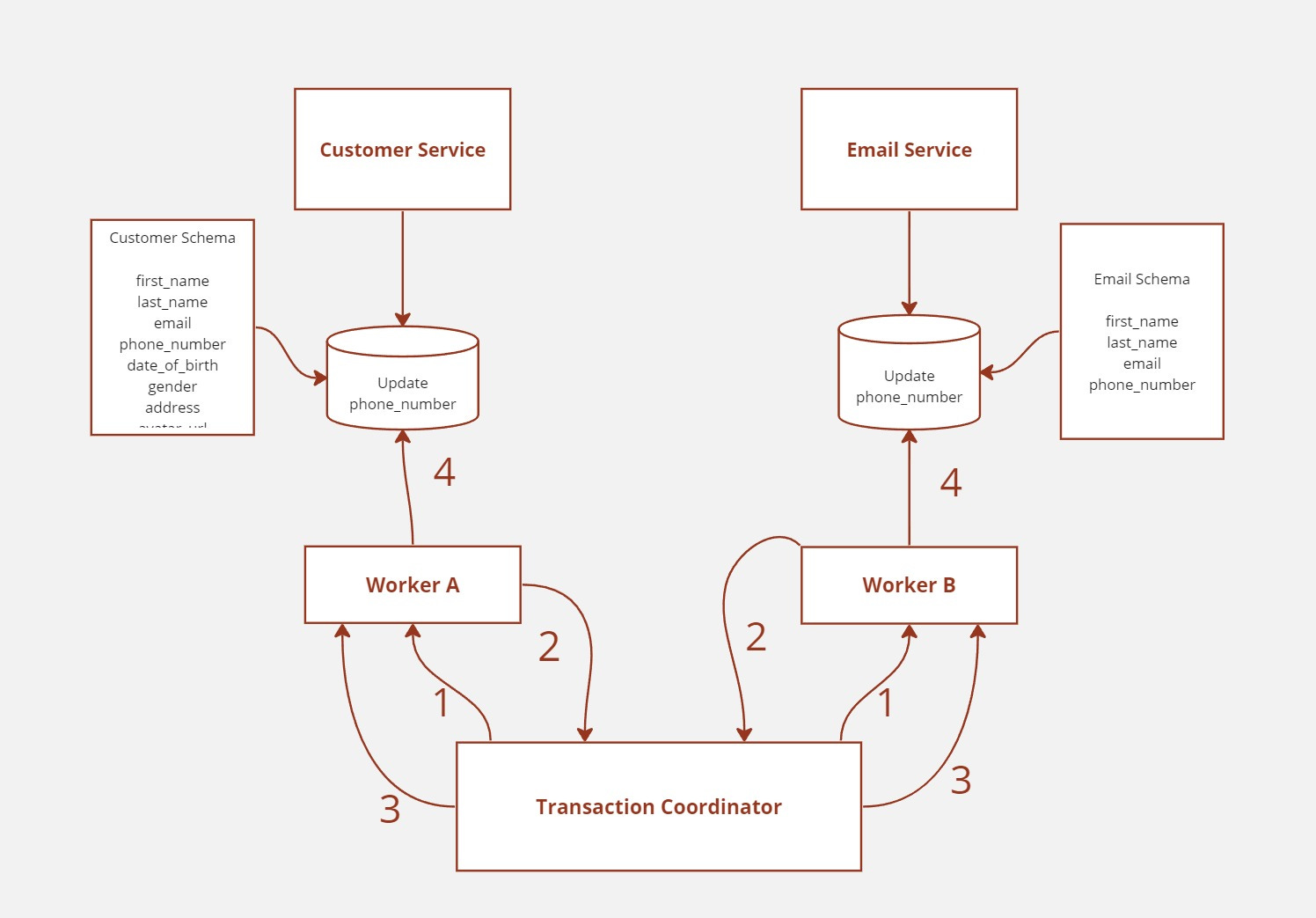
In the first step, the coordinator sends a request to the services (participants) through its workers about whether they are ready to update their states. In the second step, the services return an OK or FAIL message.
This is the first phase, also called the voting phase.
In the third step, the actual commit happens. Should the services return with an OK message, the transaction coordinator sends the payload from each service to their corresponding destinations.
However, if one of the services or even both return a FAIL message, the transaction coordinator aborts the transaction. The transaction will be committed only if every service replies with an OK message. If at least one server responds with a FAIL message, the transaction will be aborted.
In the fourth and final step, each of the services will update the state, respectively. This is because after the second step, when the database returns a response, it will put a lock on the particular rows until the transaction is completed.
This is the second phase, which is called the commit phase.
The fact that this method is unsustainable when applied to large database systems is one of its main drawbacks.
Consider a massive database table containing billions of entries and where the rows you are changing are located. The system's latency will rise if many rows are attempted to be locked for numerous transactions at the same time. We call this the long-living transaction. locking a large table for an extended length of time.
Another drawback to this strategy is that, in the unlikely event that, during the commit and voting phases, one of the services fails or its database suddenly stops accepting connections, you will have to release the locks, reverse all of the transactions, and create a retry mechanism by beginning the process all over again.
Therefore, using this method to create a microservice that is expanding rapidly is not recommended and should not be incorporated into your architecture.
Saga Pattern
For microservices architecture, the Saga Pattern is a common design pattern for handling distributed transactions. It provides a means of communication between two different services that is similar to a transaction.
The Saga Pattern entails executing multiple transactions through different services, each of which is limited to executing a single transaction while feigning to do multiple.
Furthermore, by doing extra work, you try to compensate for any shortcomings in any of the services or in any of the transactions within each service.
A saga can be controlled by all services that publish data and get subscriptions throughout the application, or it can be controlled by a single service that controls the workflow and starts the compensating logic.

An orchestrator in real life translates a composer's musical sketch into a score for an orchestra, ensemble, or choral group, assigning instruments and voices according to the composer's ideas.
When our services are orchestrated, you have a central service that will handle phoning each service in the appropriate sequence and ensure that, in the event of a failure, it is aware of how to compensate, or how to carry out the compensation action, between the services that it has already called.
Based on our example, consider that this time a registered customer wants to transition from a free trial subscription plan to a premium plan.
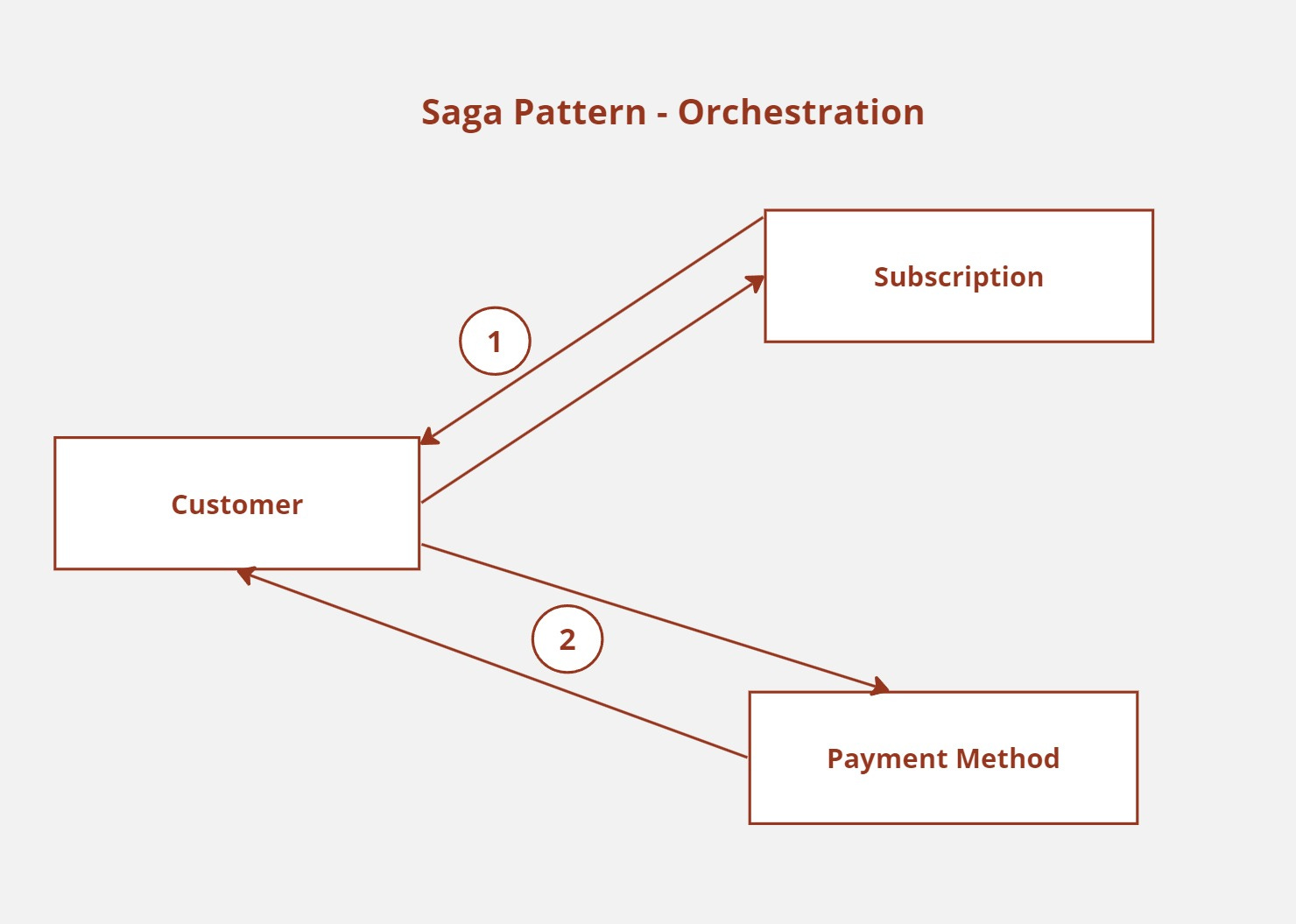
The transaction will appear in an orchestrated saga pattern, as seen in the diagram above. Customer service will take on the role of conductor in this instance. When a user clicks the Upgrade to Premium button in the user interface, the customer service representative will be called.
The customer microservice can call the subscription service and the payment method service in the right order to make sure the customer is successfully subscribed to the premium plan.
Customer service will call the subscription service and collect the necessary card details to perform payment, and then wait for the response.
When the customer service gets the response, if the response is a success, it will call the payment method service to update the customer card details for subsequent chargebacks.
Compensation must be triggered in the event that any of the phases fail. For instance, in the event that the card information is not successfully saved to the Payment Method service, the payload may be temporarily stored in an in-memory database for future attempts, or the subscription payment may be fully reverted, resulting in a refund to the consumer.

In contrast to the orchestrator, who serves as the main source of guidance during a musical performance, a choreographed dance is the process of creating patterns of movement in which each dancer uses their body in a rhythmic yet autonomous manner.
The same concept applies. Events are utilized for all interservice communication when our services are choreographed. Services react to situations and are ready to offer reimbursement or changes when something goes wrong.
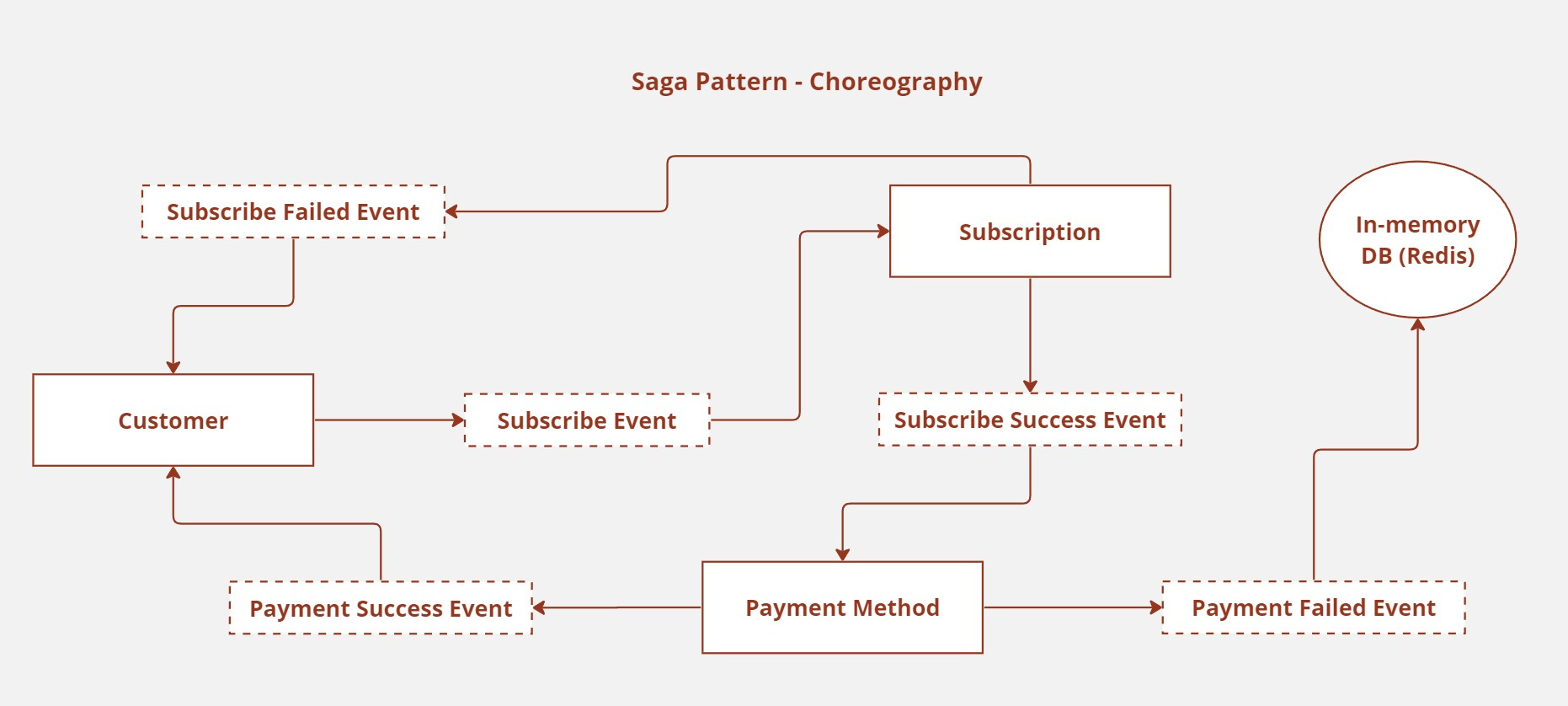
The customer service sends out an event, Subscribe Event. Other services listening to this particular event immediately reacted to it. The subscription service already knows what to do whenever this event is emitted.
It processes the customer card details for payment and upgrade to the premium plan; if successful, it immediately emits the Subscribe Success Event, and if it fails, it emits the Subscribe Failed Event.
Depending on the response emitted, the various services that listen to that event immediately react and perform the appropriate compensation task. The customer service responds to the Subscribe Failed Event and displays the appropriate message on the user interface. The payment method also reacts to the Subscribe Success Event by updating the customer payment method for subsequent chargebacks.
Finally, the payment method service updates the customer payload and emits the Payment Success Event when successful and the Payment Failed Event when failed. Customer service updates the user interface as a subscription successful when it receives the Payment Success Event.
In the case where the payment method service emits a Payment Failed Event, the payload is immediately sent to a temporary in-memory storage like Redis, so we can perform subsequent retries from there later on.
It is difficult to implement distributed transactions in a microservice architecture. Maintaining uniformity of data among many microservices.
Revisions made to one microservice might need to be mirrored in others, which makes it difficult to maintain consistency.
It frequently requires communication between several services, which adds delay. The user experience may be negatively impacted overall by performance issues and an increase in response times.
Achieving atomicity (all or nothing) in distributed transactions is difficult. If any component of the transaction fails in one microservice, it becomes challenging to ensure a rollback across all relevant services.
As a result, several strategies have been tried out over time. Two were covered in this issue: the two-phase commit and the saga pattern architecture.
The saga design presents a stronger case since the two-phase commit has proven to be ineffective in addressing the intricate need for distributed transactions.
That’s all for today. Welcome to 2024!
See you next week!