
🧠 Cold vs Warm Queries: Why Your First Query Is Always Slower
And what really happens under the hood across memory, disk, and cache layers.

Have you ever run a database query, seen it take a surprisingly long time, then immediately run it again or a similar one, and watched it fly? It’s a common puzzle when working with databases: that initial request often feels sluggish, only for subsequent ones to be lightning-fast.
This "first time" delay in databases isn't a bug; it's a fundamental aspect of how they optimize for speed. We call that initial, slower request a "cold query." It happens when the database hasn't recently accessed the specific data or components it needs for that query. On the other hand, a "warm query" is one that runs after the database has already loaded what it needs into its fast memory.
In this issue, we'll peel back the layers to understand exactly why your first database query is slower and what's happening behind the scenes to make those subsequent queries so much faster.
Cold Start Syndrome: Why Your First Query Takes Time
Imagine walking into a bakery at dawn. The ovens are cold, the dough is still in the fridge, and the coffee machine hasn’t heated up. Your croissant will take time. But come back an hour later, and the kitchen is humming — warm ovens, prepped ingredients, and a line of fresh pastries ready to go. The same concept applies to database systems.
In database terms, this is what we call a cold query — a request that reaches a system where nothing is prepped. The data pages you're trying to access are still on disk, the execution plan hasn't been compiled or cached, and the buffer pool is empty or filled with unrelated data. Even the OS page cache might be cold, forcing a full read from the underlying storage layer.
On the other hand, a warm query benefits from a system that's already in motion. The data pages are loaded in memory (either in the database buffer or OS cache), the query execution plan may have been recently compiled and stored, and if the application layer has been properly tuned, the result itself might even be waiting in a Redis or Memcached store.
Understanding the Cache Hierarchy Behind Queries
Each layer—from in-memory caches to physical storage—acts as a defensive checkpoint, trying to satisfy the request before it reaches the slower tiers.
The following diagram illustrates this flow, showing how application-level caching, database memory buffers, OS-level caching, and disk storage interact when handling a query:
💡 The deeper down the stack your query travels, the "colder" it gets—and the slower your response becomes.
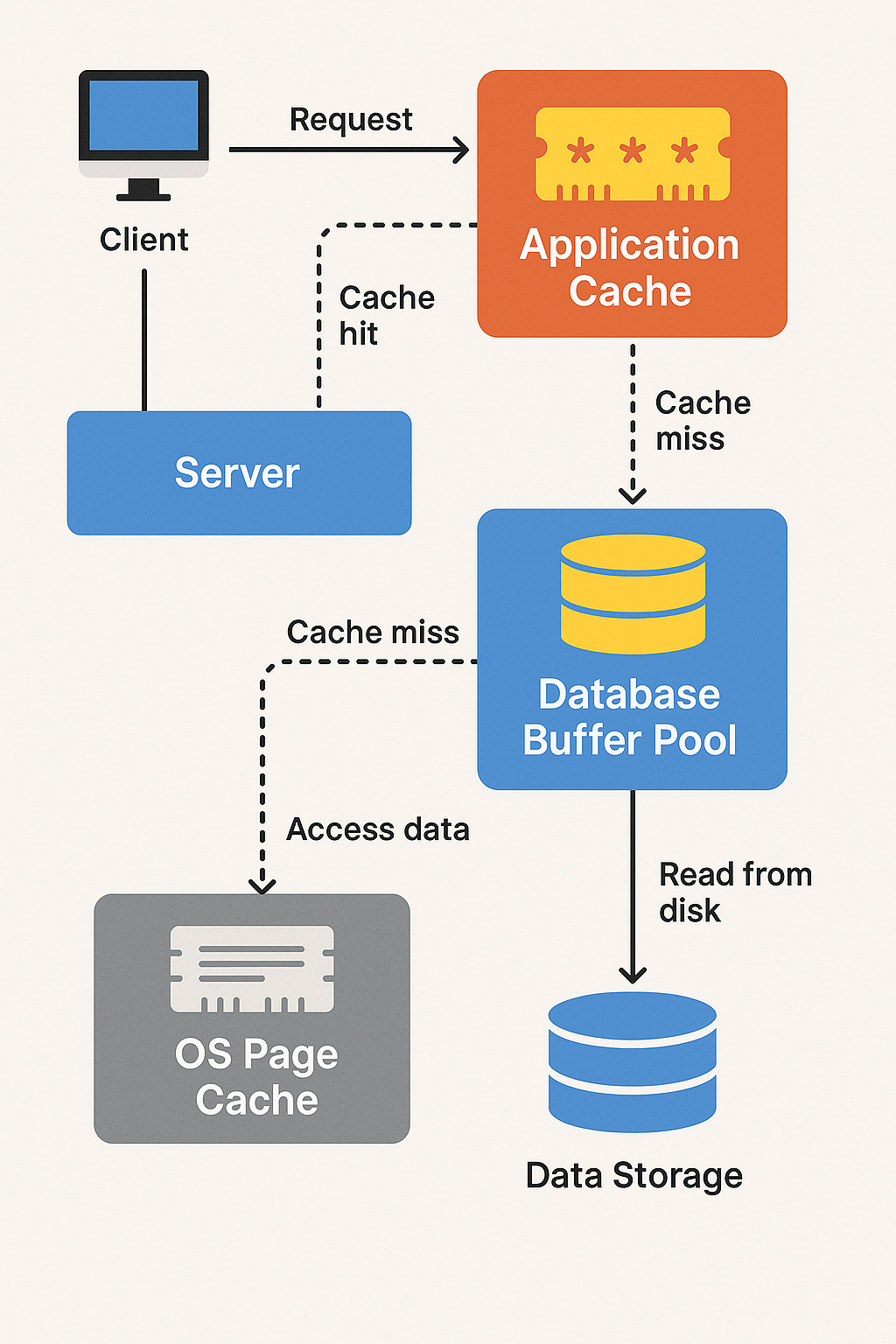
Step-by-Step Breakdown
Client sends a request → routed to the server.
Application Cache (e.g., Redis, Memcached)
First cache checkpoint.
If a cache hit, the result is returned instantly.
If a cache miss, the server proceeds to the database layer.
Database Buffer Pool (In-Memory Page Cache)
Managed by the DB engine (e.g., InnoDB, PostgreSQL shared buffers).
If the requested page is already loaded in memory, it’s a fast buffer hit.
On a buffer miss, the DB engine looks to the operating system.
OS Page Cache
The OS may already have the data in memory from a prior read.
If found, it avoids disk I/O.
Data Storage
If none of the caches have the needed data, the query hits the disk — the slowest but most reliable layer.
Strategies to Mitigate Cold Query Latency
Cold queries are inevitable—but their impact doesn’t have to be. With the right strategies, you can reduce the cost of cold queries, hide the latency from users, and even eliminate repeat cold paths altogether. Below are proven techniques used in production systems to keep things fast and responsive.
1. Proactively Warm Your Query Paths
Just like preheating an oven, you can warm your database and application caches before real users arrive.
Post-deploy warm-up scripts: Trigger key queries as soon as your app starts or after a deploy.
Startup warmers: Run a set of frequently-used queries at boot to populate the buffer pool or Redis cache.
Scheduled cache refresh: Use cron jobs to refresh long-running report queries or product catalog lookups every N minutes.
Example: After a server restart, hit your most popular endpoints with a background job so users don’t experience the cold first hit.
2. Cache Results at the Application Layer
Use tools like Redis or Memcached to cache the final results of expensive queries.
Cache only queries with a high read-to-write ratio (e.g. product pages, home feeds)
Use sensible TTLs (e.g. 5–30 minutes) for dynamic data
Invalidate based on events (e.g. product update triggers cache purge)
Bonus: Cache intermediate results for heavy aggregation queries so you don’t recompute everything from scratch.
3. Leverage Prepared Statements & Plan Caching
Query planning can introduce significant latency—especially on complex joins. Many databases support automatic or manual reuse of query plans.
In PostgreSQL, use prepared statements or client-side libraries (like
pgbouncer) to reuse compiled plans.In MySQL, older versions use a query cache; newer setups benefit more from query normalization and performance_schema plan reuse.
Tip: Avoid inline literals (e.g. WHERE id = 42) in production APIs—parameterized queries are more cache-friendly.
4. Optimize Memory & Buffer Pool Settings
Configure your database to maximize its in-memory footprint.
PostgreSQL: Tune
shared_buffers,work_mem, andeffective_cache_sizeMySQL (InnoDB): Increase
innodb_buffer_pool_sizeto store more pages in RAM
Also, allocate sufficient RAM to your OS for its page cache. This benefits cold queries by minimizing actual disk I/O.
5. Use CDN or Edge Caching (When Applicable)
If your system includes a frontend or public API layer, caching at the edge can shield your backend entirely.
Use Cloudflare, Fastly, or Varnish to cache entire API responses or static HTML
Leverage
Cache-Controlheaders for precise controlRoute long-tail or slow queries through a background fetch-and-cache mechanism
Example: For an e-commerce product page, cache the response per product ID at the CDN level with a TTL of 1–5 minutes.
Measuring Cold Query Performance in Practice
You can’t improve what you can’t observe. To effectively handle cold query latency, you need to measure it—both at the database and application levels. This section shows you how to detect cold queries, gather performance data, and simulate the cold-to-warm behavior under realistic conditions.
1. Identify Cold Queries with DB Monitoring Tools
Most modern databases offer built-in views or extensions to help track slow or uncached queries:
PostgreSQL
Use
pg_stat_statementsto track execution count, average time, and buffer hits:
SELECT query, calls, total_time, shared_blks_hit, shared_blks_read
FROM pg_stat_statements
WHERE calls < 5
ORDER BY total_time DESC
LIMIT 5;
Look for queries with highshared_blks_read and low shared_blks_hit — these are likely cold.
Pair it with
EXPLAIN (ANALYZE, BUFFERS)to see how much of the data was pulled from disk:
EXPLAIN (ANALYZE, BUFFERS) SELECT * FROM orders WHERE customer_id = 42;MySQL / InnoDB
Use InnoDB buffer pool metrics:
SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool%';Innodb_buffer_pool_reads→ Physical disk reads (cold)Innodb_buffer_pool_read_requests→ Total logical reads (including warm)
Cache efficiency:
SELECT
ROUND(100 * (1 - (P1.VALUE / P2.VALUE)), 2) AS buffer_pool_hit_rate
FROM information_schema.GLOBAL_STATUS P1
JOIN information_schema.GLOBAL_STATUS P2
ON P1.VARIABLE_NAME = 'Innodb_buffer_pool_reads'
AND P2.VARIABLE_NAME = 'Innodb_buffer_pool_read_requests';2. Simulate a Cold Query
Want to see the difference for yourself? Here's how to create a repeatable test.
PostgreSQL
# Restart PostgreSQL to flush memory (use with caution)
sudo systemctl restart postgresqlObserve the difference in execution time and buffer reads. The cold query will likely show high shared_blks_read, while the warm query shows shared_blks_hit.
MySQL
-- Cold: Restart the MySQL server or manually flush cache
FLUSH TABLES;
RESET QUERY CACHE;
-- Run query
SELECT * FROM orders WHERE id = 20001;
-- Immediately repeat
SELECT * FROM orders WHERE id = 20001;
Time the difference using your application or BENCHMARK() if testing inline.
3. Check Your Application Cache Layer
If you use Redis, Memcached, or similar tools, monitor hit ratios to catch cold paths.
# Redis
redis-cli INFO stats | grep hit
# Look at:
# keyspace_hits
# keyspace_misses
High miss counts indicate cold queries or unoptimized caching logic.
At the application level, logging cold vs warm responses (with tags like cache:MISS vs cache:HIT) helps correlate user experience with backend performance.
Summary: What You Should Watch For
Cold queries often have:
Low execution count (
calls)High disk reads (
blks_read,Innodb_buffer_pool_reads)No cache hits (Redis, Memcached)
Higher response times in logs
Warm queries:
Leverage memory (
blks_hit, buffer pool)May reuse query plans
Hit Redis or other app caches
Deliver consistent low latency
Understanding and measuring these differences is key to proactively optimizing performance and building cache-aware features.
Where Cold Queries Commonly Strike: Patterns from Production
Cold queries don’t just show up randomly — they tend to surface in predictable hotspots within a system. Below are recurring scenarios where cold starts impact latency, often in ways teams overlook until users feel it.
🛒 E-commerce Product Pages After a Cache Flush
After a deployment or Redis restart, product listing pages suddenly load slower. Why? The cached responses are gone, and each request must now hit the database and recompute filters, categories, prices, and stock availability.
How to address it:
Use a warm-up script post-deploy to repopulate cache
Cache heavy filtering or search responses for hot categories
Preload key pages into the buffer pool if possible
💳 Checkout Workflows During Off-Hours
Late at night or early morning, traffic dips. Pages like checkout or invoice rendering may load slower—not due to load, but because they’ve been inactive long enough for their buffer pages to be evicted from memory.
How to address it:
Set up scheduled pings or warmers to hit critical endpoints
Cache partial or full invoice data at the app level
Use prepared statements to eliminate plan compilation latency
📊 Admin Dashboards After Server Restarts
Dashboards that aggregate large datasets often rely on wide table scans and heavy sorting. After a restart (e.g., due to autoscaling), the system must pull everything from disk again, making first-time loads slow.
How to address it:
Replace dynamic queries with materialized views for common summaries
Keep dashboard endpoints “hot” using background refresh jobs
Tune memory settings like
work_memorsort_buffer_size
🧾 Report Generation or Export Downloads
What happens:
If a report is run only once a day or week, it’s nearly guaranteed to be cold. Add joins, filters, and aggregations across large time windows, and you're looking at minutes of disk-bound computation.
How to address it:
Precompute and store report snapshots
Use incremental rollups to avoid full-table scans
Let report generation be async and notify the user when ready
📱 Long-Tail API Endpoints and Niche Features
What happens:
Features used by 2% of users (e.g., edge-case filters, advanced search, account history exports) often don’t benefit from warmed cache or memory. But when used, they feel disproportionately slow.
How to address it:
Monitor and log cache miss patterns by endpoint
Establish tiered cache policies based on access frequency
Defer rendering with progressive loading or async queues
Conclusion…
The "cold query" phenomenon is a fundamental aspect of how modern computing systems operate. It's not a flaw, but rather a consequence of optimizing for efficiency, where frequently used resources are kept "hot" in fast memory, while less frequently used ones are relegated to slower storage or spun down to save resources.
By understanding the underlying mechanisms – be it disk I/O, cache misses, JIT compilation, or cloud cold starts – you're better equipped to design and manage your applications. While you can't entirely eliminate the "first time penalty," strategic architectural choices, proactive warming techniques, and robust caching can significantly reduce its impact. The result? A smoother, more responsive user experience and more efficient, performant systems.
Have you experienced frustrating cold starts in your own projects? What strategies have you found most effective in warming up your systems? Share your insights!